===
As a (possibly related) follow-up question, can you explain how to use the APIs to pull these types of data, and also what the categories Get, Post, Delete, and Patch mean?
Swagger (now known as OpenAPI) is a specification for building APIs. It provides a standard, language-agnostic interface to RESTful APIs. CMI-PB uses Swagger API to organize APIs and provide data access. There are multiple ways data can be downloaded from CMI-PB swagger-based API.
1) Table specific URIs: We recommend using CMI-PB API or the uniform resource identifier (URI) format i.e., https://www.cmi-pb.org/api/<table_name> to download data for each table. Database schema is avaiable at UNDERSTAND THE DATA - CMI-PB Blog pages page. This method only provides data in json format.
2) Using Curl command: Following command will return all rows in the ‘subject’ view that we created. Documentation on querying/filtering is here (Tables and Views — PostgREST 7.0.1 documentation)
3) Swagger UI: Many APIs described with Swagger provide a Swagger UI, a visual interface where you can see all available endpoints, try them out, and see their responses. You could use this UI to fetch data by hitting the relevant endpoints.
Steps with an example:
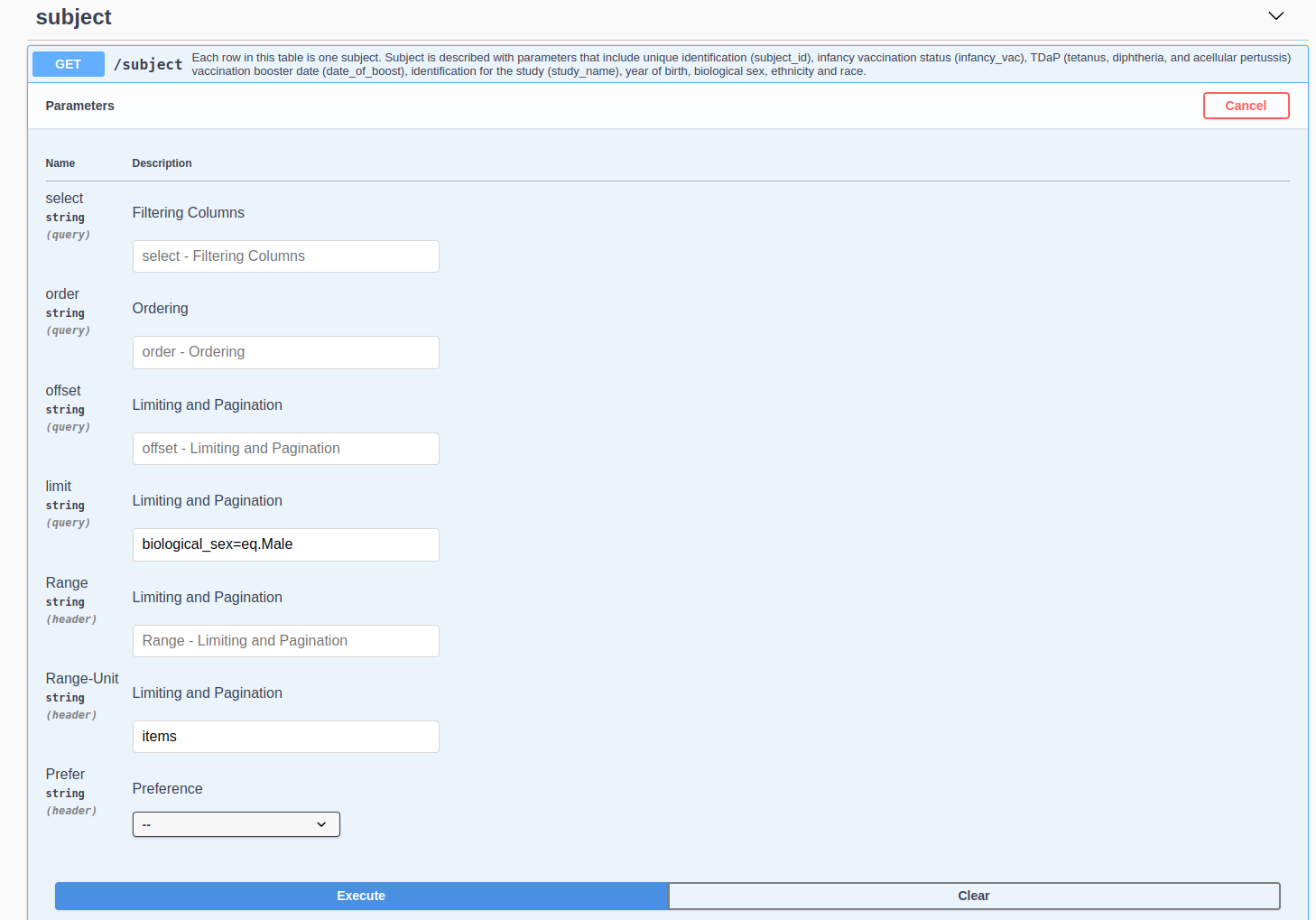
Locate the Endpoint: Once you’re on the Swagger UI, you’ll see a list of available endpoints, organized by HTTP method (GET, POST, PUT, etc.). We recomned using only GET method. Other methods are only for internal purposes. Find the endpoint from which you want to download data. Let’s say you’re looking for an endpoint that fetches subject details.
Click on the Endpoint: When you click on an endpoint in Swagger UI, it expands to show additional details, including the parameters the endpoint accepts, the expected response format, etc.
Enter Parameters (if any): If the endpoint requires any parameters (e.g., biological_sex=eq.Male in limit option), you’ll see input fields where you can enter these parameters. Fill in the necessary details.
Execute the Request: There should be a “Try it out” button or similar. Click on this button. This will execute the API request right from the browser, and Swagger UI will display the request URL, the response body, response code, and headers.
View/Download the Data: Once you execute the request:
A) The response will be displayed in the Swagger UI itself.
B) You can view the data directly in the browser in json or tsv formats.